As a data structure in R, list is not as familiar to me as vector and dataframe. I knew that list is often returned by function calls but I didn’t pay much attention to it until I started working on the API wrapper package RLeadfeeder. It turned out that list can be very useful to hold all kinds of data returned from API platforms and I had to make an effort to learn how to work with it, namely extract useful elements from a list and turn them into a dataframe.
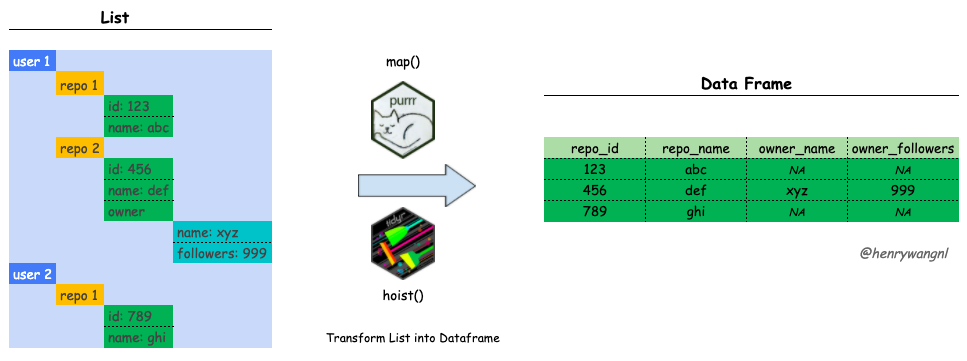
This post is an example of how to transfrom a list into a dataframe with two different approaches: tidyr and purrr. The packages used in this post are as follows:
library(tidyr) # for hoist() and unnest_longer()
library(magrittr) # for extract()
library(purrr) # for map()
library(listviewer) # for jsonedit()
library(repurrrsive) # for gh_repos dataset
Table of Contents
Inspection
Start with the inspection of list elements using listviewer package.
Task 1: Examine and understand list elements interactively.
jsonedit(gh_repos)
Extract Multiple Elements at the same level
Task 2: Extract each repository’s name and full name.
purrr approach
# replace `[` with magrittr::extract()
gh_repos %>%
map_df(~map(.x, magrittr::extract, c("name", "full_name")))
#> # A tibble: 176 x 2
#> name full_name
#> <chr> <chr>
#> 1 after gaborcsardi/after
#> 2 argufy gaborcsardi/argufy
#> 3 ask gaborcsardi/ask
#> 4 baseimports gaborcsardi/baseimports
#> 5 citest gaborcsardi/citest
#> 6 clisymbols gaborcsardi/clisymbols
#> 7 cmaker gaborcsardi/cmaker
#> 8 cmark gaborcsardi/cmark
#> 9 conditions gaborcsardi/conditions
#> 10 crayon gaborcsardi/crayon
#> # … with 166 more rows
tidyr approach
tibble(repo = gh_repos) %>%
unnest_longer(repo) %>%
hoist(repo, "name", "full_name")
#> # A tibble: 176 x 3
#> name full_name repo
#> <chr> <chr> <list>
#> 1 after gaborcsardi/after <named list [66]>
#> 2 argufy gaborcsardi/argufy <named list [66]>
#> 3 ask gaborcsardi/ask <named list [66]>
#> 4 baseimports gaborcsardi/baseimports <named list [66]>
#> 5 citest gaborcsardi/citest <named list [66]>
#> 6 clisymbols gaborcsardi/clisymbols <named list [66]>
#> 7 cmaker gaborcsardi/cmaker <named list [66]>
#> 8 cmark gaborcsardi/cmark <named list [66]>
#> 9 conditions gaborcsardi/conditions <named list [66]>
#> 10 crayon gaborcsardi/crayon <named list [66]>
#> # … with 166 more rows
Extract Multiple Elements at different levels
Task 3: Extract each repository’s name, full name, and owner’s username (
owner->login).
purrr approach
name <- gh_repos %>%
map(~map_chr(.x, "name")) %>%
flatten_chr()
full_name <- gh_repos %>%
map(~map_chr(.x, "full_name")) %>%
flatten_chr()
username <- gh_repos %>%
map(~map_chr(.x, c("owner", "login"))) %>%
flatten_chr()
tibble(name, full_name, username)
#> # A tibble: 176 x 3
#> name full_name username
#> <chr> <chr> <chr>
#> 1 after gaborcsardi/after gaborcsardi
#> 2 argufy gaborcsardi/argufy gaborcsardi
#> 3 ask gaborcsardi/ask gaborcsardi
#> 4 baseimports gaborcsardi/baseimports gaborcsardi
#> 5 citest gaborcsardi/citest gaborcsardi
#> 6 clisymbols gaborcsardi/clisymbols gaborcsardi
#> 7 cmaker gaborcsardi/cmaker gaborcsardi
#> 8 cmark gaborcsardi/cmark gaborcsardi
#> 9 conditions gaborcsardi/conditions gaborcsardi
#> 10 crayon gaborcsardi/crayon gaborcsardi
#> # … with 166 more rows
tidyr approach
tibble(repo = gh_repos) %>%
unnest_longer(repo) %>%
hoist(repo, "name", "full_name",
username = c("owner", "login"))
#> # A tibble: 176 x 4
#> name full_name username repo
#> <chr> <chr> <chr> <list>
#> 1 after gaborcsardi/after gaborcsardi <named list [66]>
#> 2 argufy gaborcsardi/argufy gaborcsardi <named list [66]>
#> 3 ask gaborcsardi/ask gaborcsardi <named list [66]>
#> 4 baseimports gaborcsardi/baseimports gaborcsardi <named list [66]>
#> 5 citest gaborcsardi/citest gaborcsardi <named list [66]>
#> 6 clisymbols gaborcsardi/clisymbols gaborcsardi <named list [66]>
#> 7 cmaker gaborcsardi/cmaker gaborcsardi <named list [66]>
#> 8 cmark gaborcsardi/cmark gaborcsardi <named list [66]>
#> 9 conditions gaborcsardi/conditions gaborcsardi <named list [66]>
#> 10 crayon gaborcsardi/crayon gaborcsardi <named list [66]>
#> # … with 166 more rows
Preference
As shown above, both approaches work fine but tidyr approach seems easier and more flexible to me. For example, considering the following question:
Task 4: Extract the full name of each user’s first repository.
tibble(repo = gh_repos) %>%
hoist(repo,
full_name = c(1, 3))
#> # A tibble: 6 x 2
#> full_name repo
#> <chr> <list>
#> 1 gaborcsardi/after <list [30]>
#> 2 jennybc/2013-11_sfu <list [30]>
#> 3 jtleek/advdatasci <list [30]>
#> 4 juliasilge/2016-14 <list [26]>
#> 5 leeper/ampolcourse <list [30]>
#> 6 masalmon/aqi_pdf <list [30]>
tibble(repo = gh_repos) %>%
hoist(repo,
full_name = list(1, "full_name"))
#> # A tibble: 6 x 2
#> full_name repo
#> <chr> <list>
#> 1 gaborcsardi/after <list [30]>
#> 2 jennybc/2013-11_sfu <list [30]>
#> 3 jtleek/advdatasci <list [30]>
#> 4 juliasilge/2016-14 <list [26]>
#> 5 leeper/ampolcourse <list [30]>
#> 6 masalmon/aqi_pdf <list [30]>
Resources
Last but not least I find these two resources are very useful for me to learn how to work with list:
- purrr tutorial: https://jennybc.github.io/purrr-tutorial/index.html
- tidyr rectangling: https://tidyr.tidyverse.org/articles/rectangle.html
How can you extract specific elements from a list and convert them into a dataframe for further analysis or manipulation?
bWoX6CunGFV